一、前言
在leetcode-01-两数之和的题目中,提到了hash table 在查找方面提高时间复杂度的表现。本片文章是对hashmap进行详细的学习。
二、java中其他数据结构在新增和查找方面的表现
- 数组:
- 1.1 无序数组:
- 查找:时间复杂度时O(n)
- 新增:时间复杂度O(1)
- 1..2 有序数组
- 查找:使用二分查找,差值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn)。但当实际需要插入删除操作时,由于涉及到数组元素的移动,平均时间复杂度为O(n)
- 1.1 无序数组:
- 线性链表:
- 查找:O(n)
- 新增: O(1) ,因为仅需引用变换,无序元素移动
二叉树:(本质:物理组织结构为链表)
- 插入&查找&删除:O(logn)
- 哈希表:(本质:主干物理组织结构是数组)
- 查找:O(1) 当不存在哈希冲突时
三、HashMap
哈希函数和哈希冲突
- HashMap利用哈希函数:hash表使用了数组的形式,当涉及到查找的时候,通过哈希函数计算的hash值,可以快速得到值对应的数组下标,定位到相应元素,时间复杂度为O(1)
解决哈希冲突:不可避免。哈希冲突的解决方案有多种:
- 开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)
- 再散列函数法 ?
- 链地址法 ?
而HashMap即是采用了链地址法,也就是数组+链表的方式
数据+链表的HashMap结构图
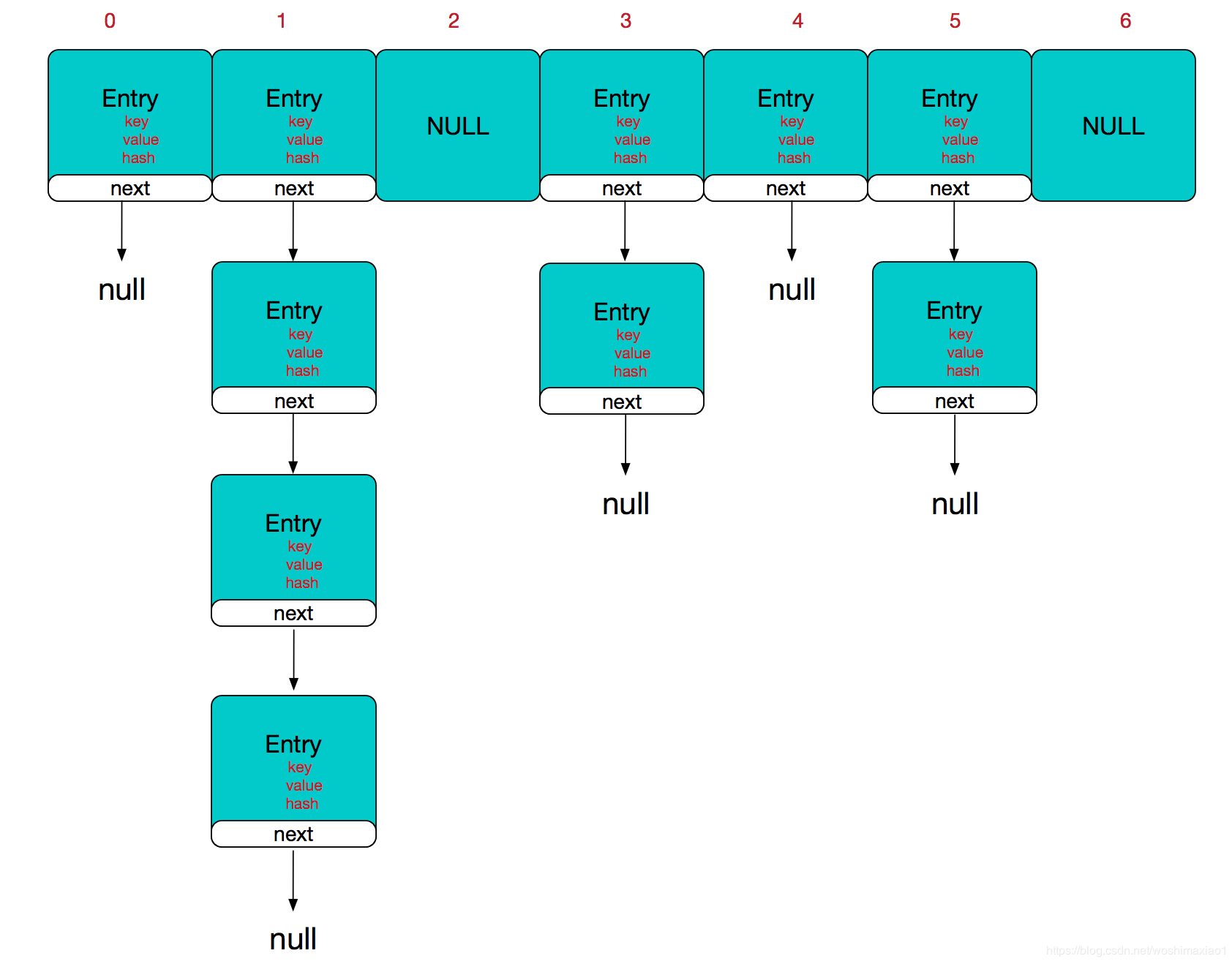
数组是hashmap的主体,链表是为了解决哈希冲突。如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
之后有介绍了hashmap在不同的构造器下,新增put和查找get的具体步骤,源码解析。目前还不需要了解这么深入。待进一步学习。